소개
이 글은 다음 사이트를 참고하여 작성되었습니다.
Reference site
Understanding memory usage in deep learning models training
Shedding some light on the causes behind CUDA out of memory ERROR, and an example on how to reduce by 80% your memory footprint with a few lines of code in Pytorch
www.sicara.fr
https://github.com/cybertronai/gradient-checkpointing
GitHub - cybertronai/gradient-checkpointing: Make huge neural nets fit in memory
Make huge neural nets fit in memory. Contribute to cybertronai/gradient-checkpointing development by creating an account on GitHub.
github.com
본문
Gradient checkpointing 기법은 인공지능이 training할 때 메모리를 적게 사용하게 하는 기법입니다. 일반적으로 DNN은 forward 연산에서 각 layer의 출력값을 모두 저장합니다. backpropagation에서 사용되는 gradient descent 기법에서 미분 연산의 chain rule 때문에, forward 연산의 layer의 출력값이 필요로 하기 때문입니다. 따라서 training 과정 중, backpropagation을 위해 forward 연산에서 각 layers의 출력 값들은 모조리 저장되어야 합니다. 직관적으로 보았을 때 layer가 많을 수록, 그리고 layer의 출력이 많을 수록 forward 연산에서 저장되는 값들의 양을 증가하겠죠. 이때의 저장되는 값들을 activation이라고 부르겠습니다.
예를 들어 어떤 모델에 hidden layer 2개가 있고, 그 hidden layers의 종류가 Dense layer라고 가정해 보겠습니다. 여기서 각각의 dense의 출력 개수는 16, 32개라고 가정하겠습니다. 첫 번째 Dense layer의 출력이 16개이고, 한 출력당 4bytes(float32 bits)를 차지하기 때문에 첫 번째 출력(activation)의 메모리 사용량은 64bytes가 됩니다. 두 번째 dense layer의 출력이 32개이기 때문에 두 번째 층의 activation의 메모리 사용량은 128bytes가 됩니다. 즉, 이 모델의 activation의 메모리 사용량은 64 + 128 = 192bytes가 되는 거죠.
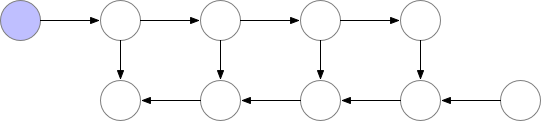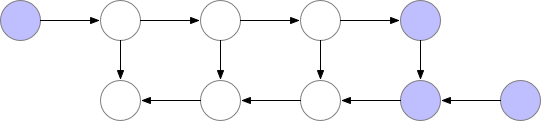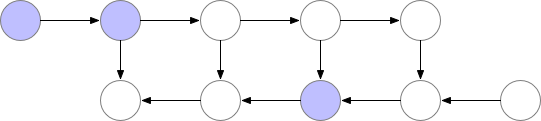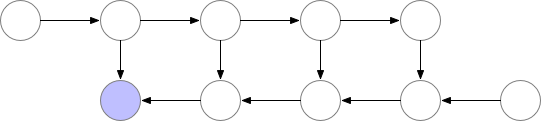
아래의 그림은 왜 forward activation이 backproprgation을 위해 모조리 저장되어야 하는지를 보여줍니다.
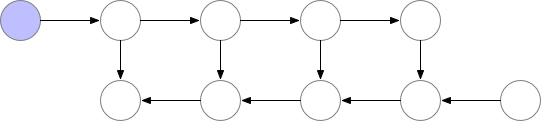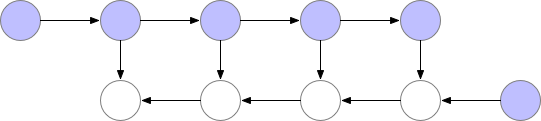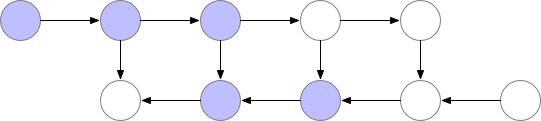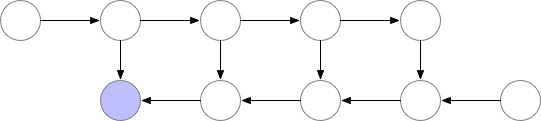
위의 그림은 일반적인 forward와 backpropagation의 모습입니다.
위의 첫 번째 줄은 forward 연산을 의미하며, 각각의 동그라미는 layer를 의미하고, 보라색은 layer의 연산 결과(activation)가 메모리에 저장되었다는 의미입니다. 두 번째 줄은 backpropagation의 기울기 값을 의미하며, 보라색은 기울기 값이 메모리에 저장되었다는 의미입니다.
그림에서 알 수 있듯, forward 연산 시에는 모든 activation이 저장되어 있다가, backpropagation이 수행되면 순서대로 activation들이 메모리에서 제거됨을 알 수 있습니다. 이는 backpropagation에서 forward 연산의 activation이 필요가 없어짐을 의미하죠.
여기서 만약 다음과 같이 연산이 된다면 어떻게 될까요?
위의 그림은 특정 layer의 기울기가 필요한 때마다 forward 연산을 처음부터 다시 하는 것을 알 수 있습니다.
첫 번째 그림과 비교했을 때, 보라색 동그라미의 양(메모리 사용량)이 확연히 줄어든 것을 알 수 있습니다. 하지만, 이 방법에서는 forward 연산을 처음부터 다시 해야하기 때문에, 연산량이 너무 많아집니다. 즉, 모델의 학습 속도가 현저히 낮아질 수 있음을 의미하죠. 하지만, 단순히 연산을 다시하는 것이기 때문에 정확도의 차이는 없습니다. 이 점이 다른 memory efficient 기법(ex mixed precision)과의 차이라고 할 수 있습니다.
Gradient checkpointing은 첫 번째 방법과 두 번째 방법의 절충안입니다. forward 연산에서 중간의 어느 임의의 지점을 저장하고, backpropagation시 저장된 그 지점에서부터 다시 연산을 하는 것입니다.

위의 그림에서는 forward 연산할 때, 두 번째 지점에서 값을 저장하는 것을 알 수 있습니다. 이를 :checkpointing한다"라고 하며, 그 지점을 checkpoint라고 합니다. 여기서는 두 번째 지점이 checkpoint겠죠. Gradient checkpointing 기법은 필요에 따라 checkpoint 지점에서 다시 연산을 하는 겁니다. 이렇게 하면 두 번째 방법인 "처음부터 다시 연산한다"와 첫 번째 방법인 "모든 activation을 저장한다."의 절충안이 되는 거겠죠. 즉, "임의의 지점에서 activation을 저장하고, 그 지점에서 다시 연산한다."입니다.
이러면 첫 번째 방법에 비해 activation을 저장하기 위한 memory를 아낄 수 있으며, 처음부터 연산을 하지 않기 때문에 연산량(computation)을 줄일 수도 있는 효율적인 방법이 됩니다. 또한 모델의 정확도에 영향을 주지 않는 것도 장점이라고 할 수 있죠.
github의 cybertronai이 테스트한 결과는 다음과 같습니다.
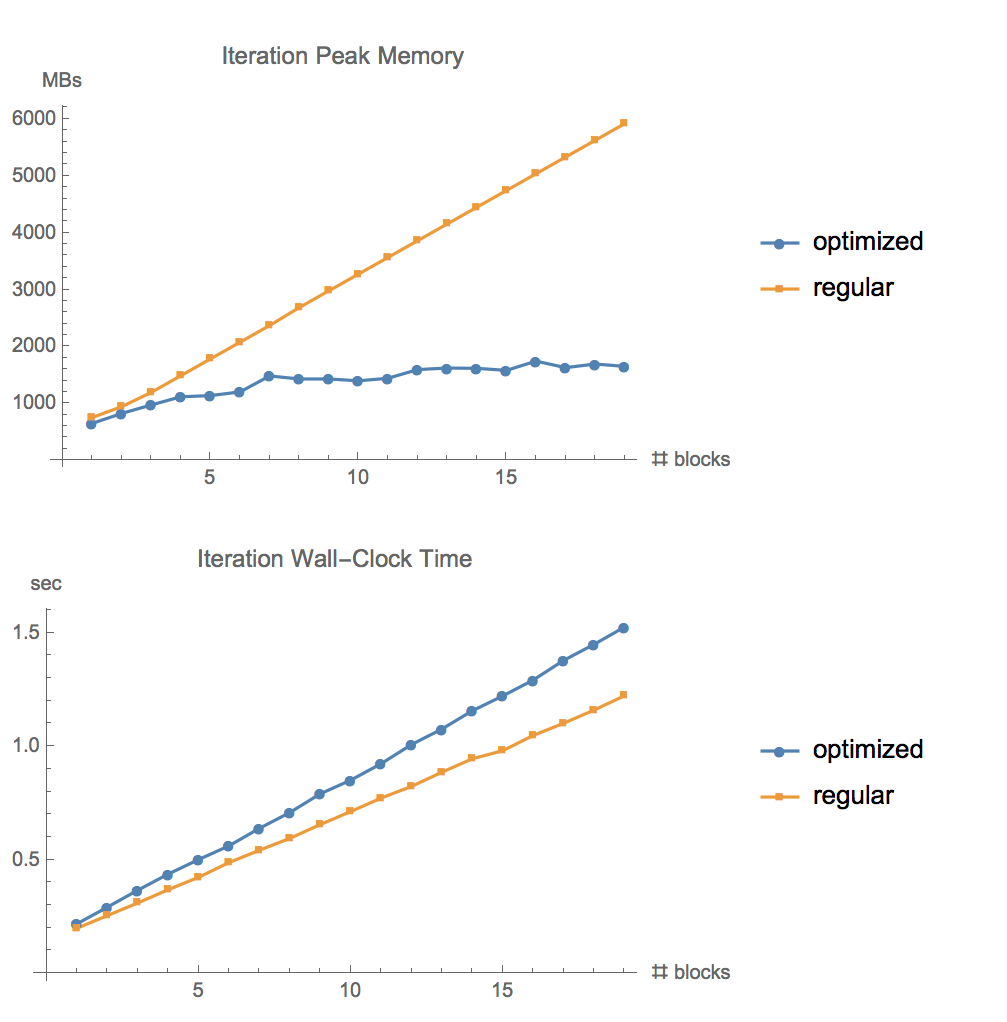
첫 번째 그림은 메모리 사용량, 두 번째 그림은 연산이 얼마나 느린지를 보여줍니다.
첫 번째 그림에서 노란 선은 기존의 "모든 activation을 저장"하는 방식입니다. 파란 선은 gradient checkpointing을 사용한 기법입니다. 보시다시피 gradient checkpointing 기법을 사용한 모델이 메모리를 적게 사용한다는 것을 알 수 있습니다.
두 번째 그림에서 파란 선이 노란 선보다 약간 위에 있음을 알 수 있습니다. 이는 모델을 학습할 때 gradient checkpointing 기법이 기존의 방식보다 약간 오래 걸린다는 것을 보여줍니다.
결론
Gradient checkpointing 기법은 training 시, 메모리를 아낄 수는 있지만, 대신 computation(연산)량이 많이짐을 알 수 있습니다. checkpoint의 개수에 따라 메모리 사용량과 연산량의 차이가 있기에 이 또한 hyperparameter가 될 수 있습니다.
Gradient checkpointing은 메모리가 부족한 mobile 환경이나, MCU 같은 환경에서 training 시, 효과적인 기법이라고 할 수 있습니다.
Gradient checkpointing은 단순히 연산을 다시하는 것이기 때문에 모델의 정확도 변화는 없다는 것이 장점이라고 할 수 있습니다. (mixed precision과의 차이점)
'인공지능 대학원 자료 정리 > 참고 정리' 카테고리의 다른 글
| ImageNet 다운로드에서 사용하기까지 [Kaggle 이용] (0) | 2022.12.27 |
|---|
