관련글
Optimizer RAdam (2019)
논문 제목: ON THE VARIANCE OF THE ADAPTIVE LEARNING RATE AND BEYOND
연도: 2019
링크: https://arxiv.org/pdf/1908.03265.pdf
관련 개념:
1. Adam
2. variance
3. learning rate warm-up
서론
Adam이라는 optimizer는 단점에도 불구하고 넓은 분야에서 사용되고 있습니다. Adam의 대표적인 단점은 다음과 같습니다.
1. 학습률이 기하급수적으로 늘 수도 있다.
2. 학습을 너무 빨리 하여, local minima에 빠르게 도달할 수 있다.
RAdam은 2번의 문제를 완화한 optimizer로, 초기에 불안정하게 학습하는 Adam의 특성을 분석하여 고안되었습니다.
RAdam은 Adam보다 성능이 좋고, 안정성도 높다고 하네요. 심지어 step size 다양한에도 유사한 결과를 보인다고 합니다.
본론
Adam은 Warmup 기법이 없으면, 안 좋은 local optima에 빠지는 경우가 있습니다. 예를 들어 Transformer 계열의 모델에서 실험했을 때, warmup이 없다면, loss가 3에서 10까지 상승한다고 합니다. 이러한 상황은 BERT를 pre-training할 때도 목격된다고 합니다. 물론 'warmup이라는 기법을 사용하면 되는 거 아닌가?'라고 생각하실 수 있지만, warmup이라고 나온 기법들은 대부분 사람이 직접 warmup 함수를 고안하고, 얼만큼의 warmup을 해야하며, 어느 정도의 크기로 warmup을 해야 하는지 등 여러 고려 사항들이 많습니다.
논문에서는 Adam의 문제를 이론적으로 보여줌으로써 이에서 영감을 얻은 RAdam(Rectified Adam)을 소개합니다. 다음은 논문에 나온 Adam의 문제점입니다.
Adam의 문제점

왼쪽은 Transformer에 warmup이 없는 Adam을 적용했을 때의 gradients의 분포이며, 오른쪽은 warmup을 적용했을 때의 gradients의 분포입니다. 왼쪽 그림은 초기 10 updates 동안 gradients의 분포가 상당히 변한 것에 비해, 오른쪽은 거의 변하지 않았다고 할 볼 수 있습니다. 이를 보고 '왼쪽이 학습이 빨리된 거 아냐?'라고 생각하실 수도 있지만, 학습의 의미는 gradient의 변화가 작은 것으로 볼 수 있기 때문에, 오른쪽이 학습이 빨리된 것이라고 할 수 있습니다. 또한 오른쪽이 더 안정적이라는 것은 바로 아실 수 있을 것입니다.
warmup을 사용 안 할 시, 초기에 이상한 분포가 나오는 것을 저자들은 이렇게 표현했습니다.
"Due to the lack of samples in the early stage, the adaptive learning rate has an undeisrably large variance, which leads to suspicious/bad local optima."
"초기에는 샘플이 적기 때문에, adaptive learning rate가 바람직하지 못하게 너무 커지며 이로인해 안 좋은 local optima에 빠진다.
저자들은 RAdam과 별개로 warmup 없이 초기의 Adam을 안정시킬 수 있는 실험을 진행했습니다. (블로그에서는 이 방법들을 소개만합니다.) 첫 번째는 초기의 2000번의 학습에만 2차 momentum을 업데이트 하기, 두 번째는 epsilon의 크기를 늘리기 입니다.
RAdam algorithm

위의 수식은 RAdam의 의사코드입니다. 위의 알고리즘에서 p는 시간에 따라 증가하는 값으로 p가 4보다 크면, 2차 momentum인 v가 반영된 l과 r이 update 식에 반영되며, 4보다 작거나 같으면 기존의 SGD momentum 수식만 적용된 것을 알 수 있습니다. 즉, 어떤 t 시점 이하에서는 모멘텀을 사용하며, 그 이후에는 저자들이 고안한 수식에 따라 Adam과 비슷하게 2차 momentum이 적용된 update가 수행된다는 것을 알 수 있습니다.
l은 기존의 Adam에 있는 v와 v_hat을 합쳐 놓은 항으로, 기존의 Adam의 2차 모멘텀 식과 동일하다는 것을 알 수 있으며, r은 새로 도입된 항으로, gradient를 규제하는 항으로 작용한다고 나와 있습니다.
아래는 SGD와 Adam 그리고 RAdam의 성능을 비교한 그림입니다.

녹색은 RAdam, 붉은색은 Adam, 푸른색은 SGD를 나타내고 있습니다. 상황에 따라 다르지만, 대체적으로 RAdam이 Adam보다 test와 train 성능이 좋다는 것을 알 수 있습니다. (SGD는 일반화 성능이 좋기 때문에 train에서는 약세를 보이지만, "test에서 Adam보다 우세할 수 있다"라는 의견이 현재 optimizer의 동향입니다. 그래서 test 정확도가 SGD가 더 높네요.)
다음은 learning rate에 따라 RAdam과 Adam 그리고 SGD의 성능이 어떻게 달라지는지 보여주고 있습니다.
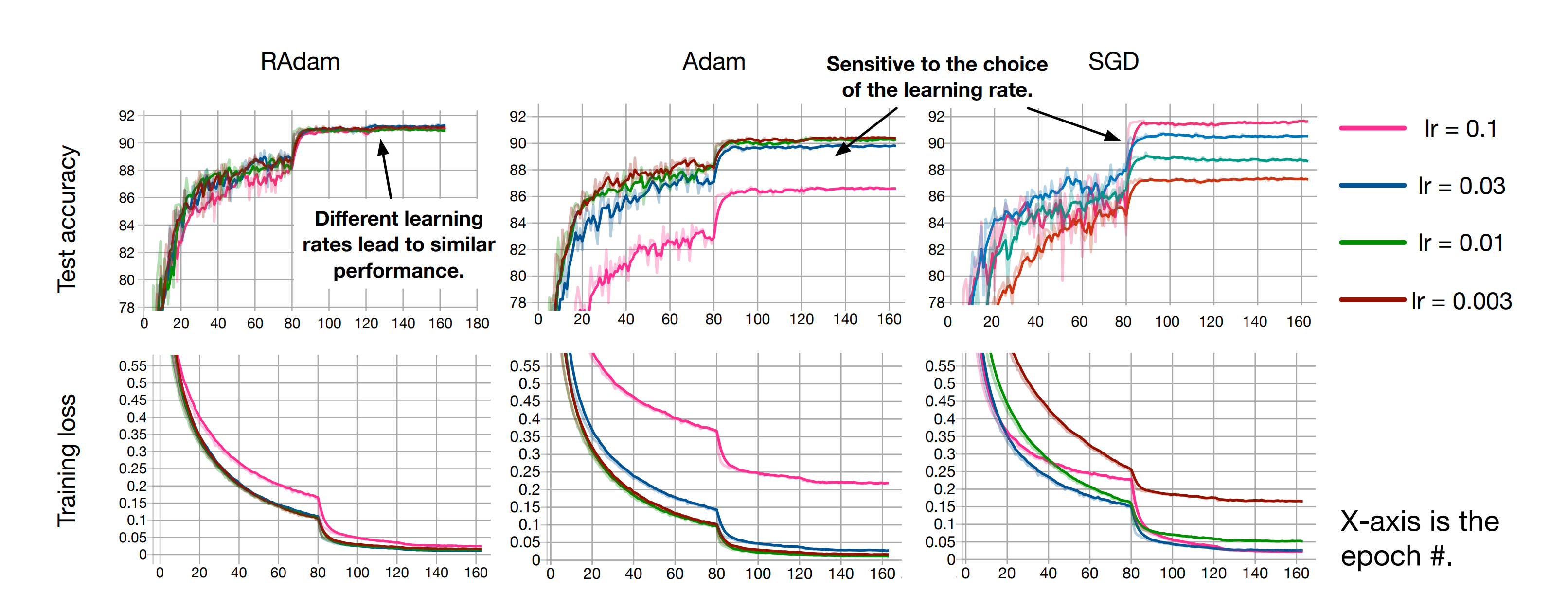
보시다시피, RAdam은 learning rate가 변해도 비교적 성능상의 큰 차이가 없다는 것을 볼 수 있습니다. 이것을 우리는 learning rate robust하다고 얘기합니다.
논문을 보시면 아시겠지만, Figure 7에서 볼 수 있듯, Adam에 warmup을 적용했을 때와 RAdam을 사용했을 때 유사한 성능을 보이거나 RAdam이 더 뛰어나다는 것을 볼 수 있었습니다.
결론
장점
| 1. 초기의 불안정한 Adam의 단점을 완화했다. 2. learning의 변화가 acc의 변화에 직결되지는 않는다. 3. 일반화 성능이 Adam보다 비슷하거나 낫다. 4. 수식이 직관적이며, 기존의 Adam에서 크게 변화하지는 않았다. |
단점
| 1. 추가적인 비선형 연산이 들어가기에 MCU 같은 End nodes에서는 사용하기 쉽지 않다. 즉, on board training이 힘들 수 있다. |
참고
https://arxiv.org/abs/1908.03265
On the Variance of the Adaptive Learning Rate and Beyond
The learning rate warmup heuristic achieves remarkable success in stabilizing training, accelerating convergence and improving generalization for adaptive stochastic optimization algorithms like RMSprop and Adam. Here, we study its mechanism in details. Pu
arxiv.org
'인공지능 대학원 자료 정리 > 옵티마이저 (Optimizers)' 카테고리의 다른 글
| 옵티마이저 정리 및 논문 리뷰 (2023-10-29 수정) (0) | 2023.10.29 |
|---|---|
| 옵티마이저 Lookahead (2019, 안정적인 학습 도모) (0) | 2022.12.12 |
| 옵티마이저 종류들 (0) | 2022.11.23 |
| 옵티마이저 SM3 (2019, 메모리 효율적) (0) | 2022.11.23 |
| 옵티마이저 Adafactor (2018, 메모리 효율적) (2) | 2022.11.22 |



